MaxViT¶
Transformer Vision Transformer Image Classification
- class lucid.models.MaxViT(in_channels: int = 3, depths: tuple[int, ...] = (2, 2, 5, 2), channels: tuple[int, ...] = (64, 128, 256, 512), num_classes: int = 1000, embed_dim: int = 64, num_heads: int = 32, grid_window_size: tuple[int, int] = (7, 7), attn_drop: float = 0.0, drop: float = 0.0, drop_path: float = 0.0, mlp_ratio: float = 4.0, act_layer: type[~lucid.nn.module.Module] = <class 'lucid.nn.modules.activation.GELU'>, norm_layer: type[~lucid.nn.module.Module] = <class 'lucid.nn.modules.norm.BatchNorm2d'>, norm_layer_tf: type[~lucid.nn.module.Module] = <class 'lucid.nn.modules.norm.LayerNorm'>)¶
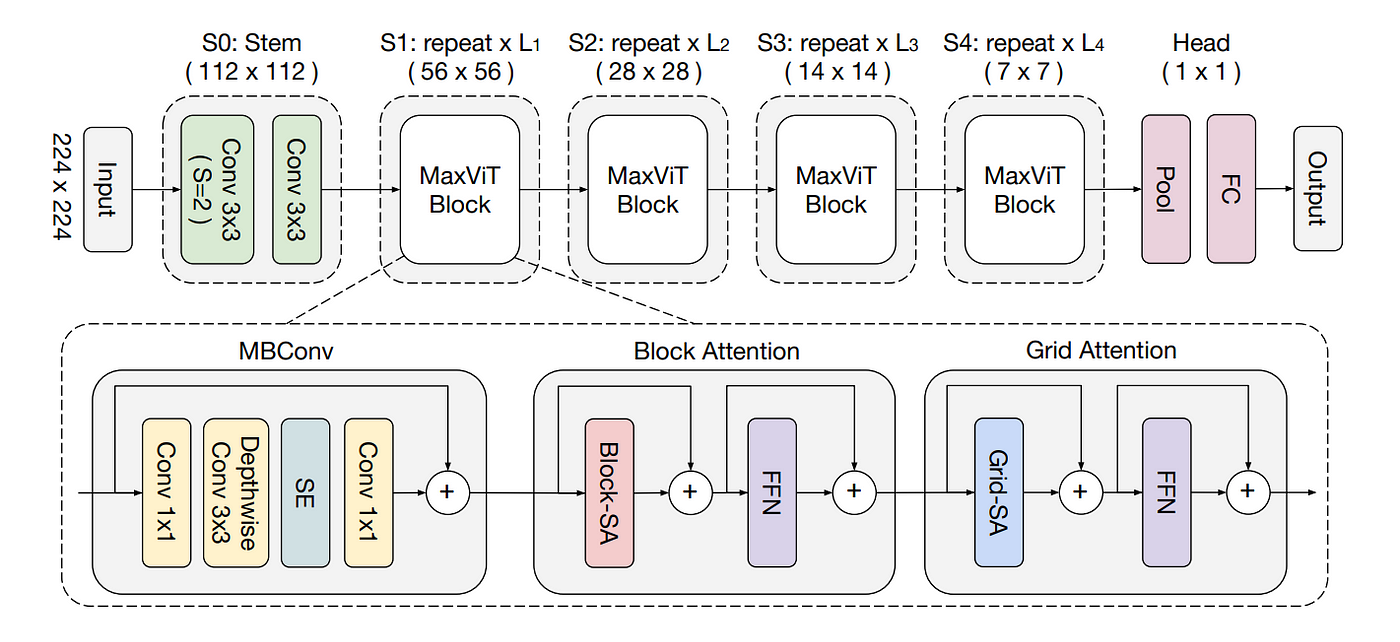
The MaxViT module implements the Multi-Axis Vision Transformer architecture, which combines local and global attention using a novel block design featuring convolution, window attention, and grid attention stages.
Class Signature¶
class MaxViT(nn.Module):
def __init__(
in_channels: int = 3,
depths: tuple[int, ...] = (2, 2, 5, 2),
channels: tuple[int, ...] = (64, 128, 256, 512),
num_classes: int = 1000,
embed_dim: int = 64,
num_heads: int = 32,
grid_window_size: tuple[int, int] = (7, 7),
attn_drop: float = 0.0,
drop: float = 0.0,
drop_path: float = 0.0,
mlp_ratio: float = 4.0,
act_layer: type[nn.Module] = nn.GELU,
norm_layer: type[nn.Module] = nn.BatchNorm2d,
norm_layer_tf: type[nn.Module] = nn.LayerNorm,
)
Parameters¶
in_channels (int, optional): Number of input image channels. Default is 3.
depths (tuple[int, …], optional): Number of MaxViT blocks in each stage. Default is (2, 2, 5, 2).
channels (tuple[int, …], optional): Number of channels in each stage. Default is (64, 128, 256, 512).
num_classes (int, optional): Number of output classes for classification. Default is 1000.
embed_dim (int, optional): Embedding dimension for the initial convolution. Default is 64.
num_heads (int, optional): Number of attention heads for both window and grid attention. Default is 32.
grid_window_size (tuple[int, int], optional): Size of window and grid used in attention blocks. Default is (7, 7).
attn_drop (float, optional): Dropout rate for attention weights. Default is 0.0.
drop (float, optional): Dropout rate for MLP and projection outputs. Default is 0.0.
drop_path (float, optional): Drop path (stochastic depth) rate. Default is 0.0.
mlp_ratio (float, optional): Ratio of MLP hidden dimension to embedding dimension. Default is 4.0.
act_layer (type[nn.Module], optional): Activation layer used in MLPs. Default is nn.GELU.
norm_layer (type[nn.Module], optional): Normalization layer used in convolution stages. Default is nn.BatchNorm2d.
norm_layer_tf (type[nn.Module], optional): Normalization layer used in transformer blocks. Default is nn.LayerNorm.
Architecture¶
MaxViT is composed of four key stages:
Convolutional Stem: - Processes the input image to obtain a patch-level feature map.
MaxViT Blocks: - Each stage includes:
MBConv Block for local spatial learning.
Window Attention to capture fine-grained local dependencies.
Grid Attention to model global interactions across non-overlapping partitions.
Stage-wise Depths and Channels: - Allows progressive increase in capacity and receptive field.
Classification Head: - Global pooling followed by a linear classifier.
Mathematical Representation¶
MaxViT alternates between two types of multi-head attention:
Window Attention:
Grid Attention (shifted spatial axis):
These attention mechanisms operate in localized (window) and global (grid) spaces.
Examples¶
Basic Usage
import lucid
from lucid.models.transformer import MaxViT
model = MaxViT()
input_tensor = lucid.randn(1, 3, 224, 224)
output = model(input_tensor)
print(output.shape) # (1, 1000)
Custom Configuration
model = MaxViT(
in_channels=3,
depths=(2, 3, 4, 2),
channels=(64, 128, 256, 512),
num_classes=10,
embed_dim=96,
num_heads=8,
grid_window_size=(7, 7)
)
input_tensor = lucid.randn(1, 3, 224, 224)
output = model(input_tensor)
print(output.shape) # (1, 10)
Note
The number of stages in MaxViT is determined by the length of depths and channels.
Tip
Use larger grid_window_size for inputs with high spatial resolution to improve global attention coverage.
Warning
Ensure that num_heads divides the embedding dimension cleanly to prevent shape mismatch in attention computation.
Implementation Details¶
MaxViT, introduced by Tu et al., integrates convolution and transformer mechanisms. It uses MBConv, window attention, and grid attention in series to model both local and long-range dependencies efficiently.
MaxViT’s distinctive design improves training stability and performance on image classification tasks, particularly on large datasets with diverse object scales.
MBConv: Efficient spatial feature learning with residual connections.
Window Attention: Captures local patch-level context.
Grid Attention: Enables long-range interaction via shifted partitions.
Classification Head: Uses global average pooling followed by a linear projection.