ViT¶
Transformer Vision Transformer Image Classification
- class lucid.models.ViT(image_size: int = 224, patch_size: int = 16, in_channels: int = 3, num_classes: int = 1000, embedding_dim: int = 768, depth: int = 12, num_heads: int = 12, mlp_dim: int = 3072, dropout_rate: float = 0.1)¶
The ViT class provides a full implementation of the Vision Transformer model, including patch embedding, positional encoding, and the final classification head.
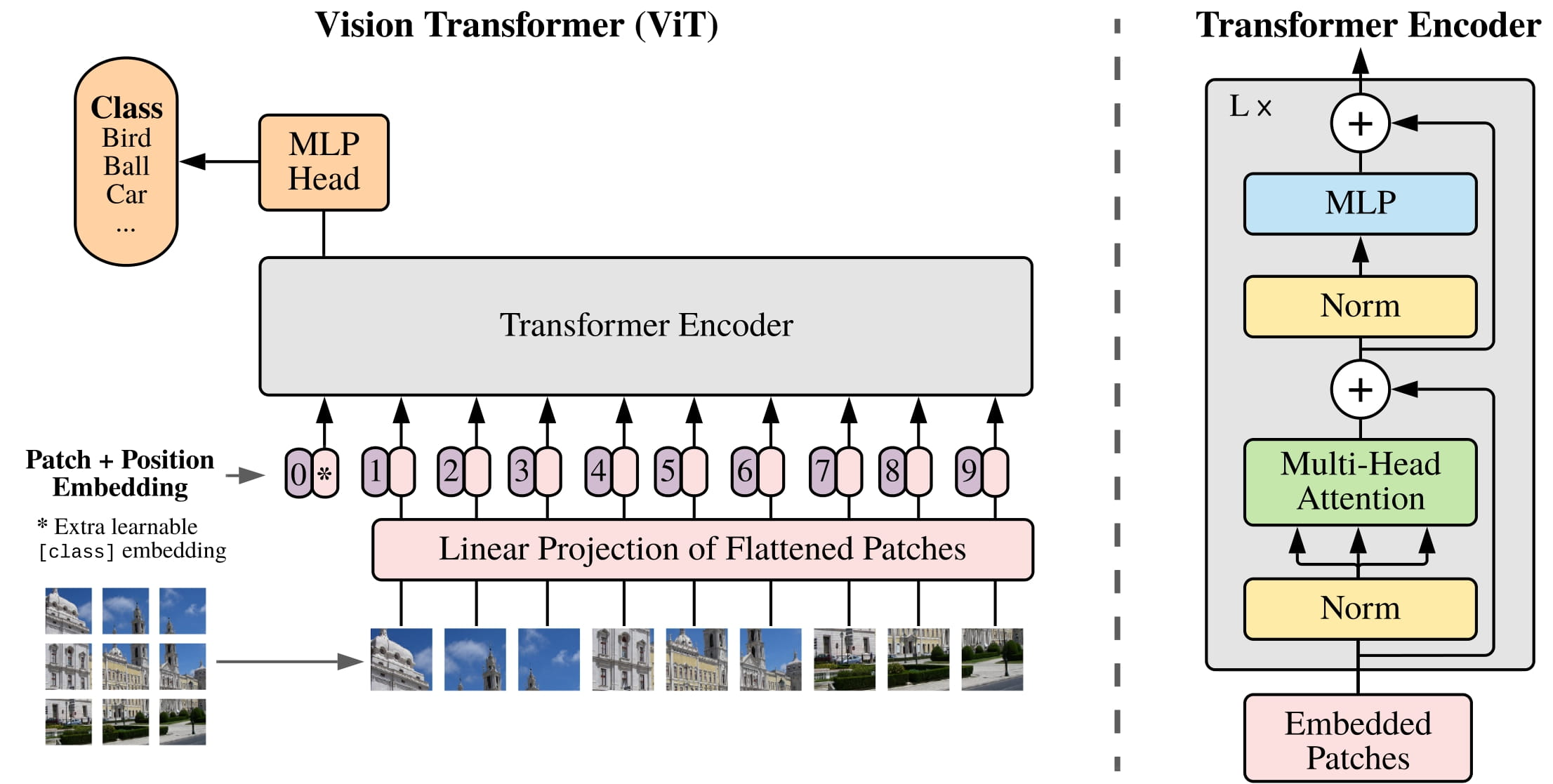
Class Signature¶
class ViT(
img_size: int,
patch_size: int,
num_classes: int,
d_model: int,
num_heads: int,
num_layers: int,
mlp_dim: int,
dropout: float = 0.1,
)
Parameters¶
img_size (int): Size of the input image (assumes square images).
patch_size (int): Size of the patches the image is divided into.
num_classes (int): Number of output classes for classification.
d_model (int): Dimension of the model’s hidden representations.
num_heads (int): Number of attention heads in the multi-head self-attention mechanism.
num_layers (int): Number of Transformer encoder layers.
mlp_dim (int): Dimension of the feedforward network within each Transformer block.
dropout (float, optional): Dropout probability applied throughout the model. Default is 0.1.
Examples¶
>>> import lucid.models as models
>>> vit = models.ViT(
... img_size=224,
... patch_size=16,
... num_classes=1000,
... d_model=768,
... num_heads=12,
... num_layers=12,
... mlp_dim=3072,
... dropout=0.1
... )
>>> print(vit)
ViT(img_size=224, patch_size=16, num_classes=1000, d_model=768, ...)