Transformer¶
Transformer Sequence-to-Sequence
- class lucid.models.Transformer(src_vocab_size: int, tgt_vocab_size: int, d_model: int, num_heads: int, num_encoder_layers: int, num_decoder_layers: int, dim_feedforward: int, dropout: float = 0.1)¶
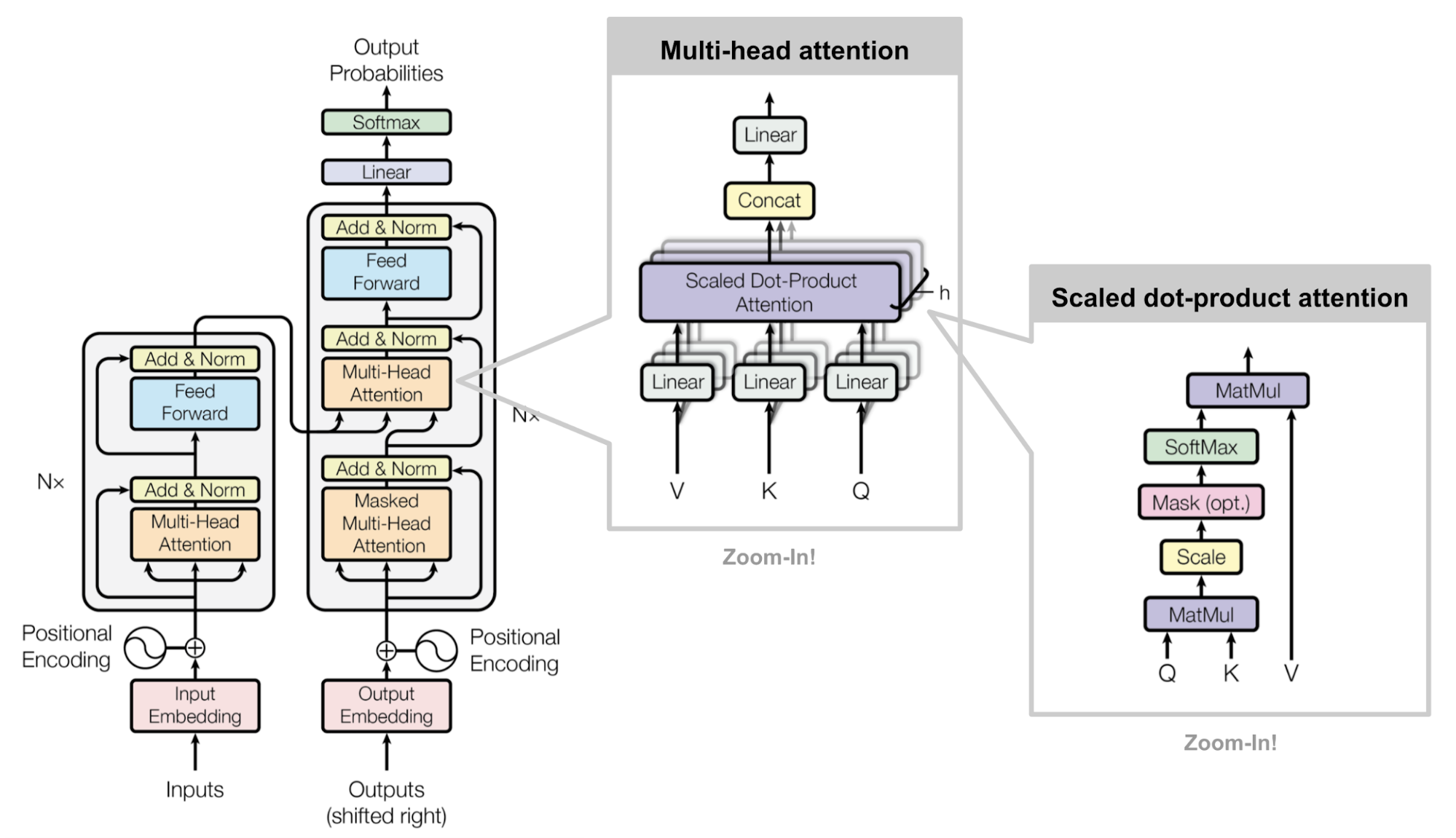
The Transformer class in model provides a full implementation of the Transformer model, including positional encoding and the final vocabulary projection. This is distinct from nn.Transformer, which serves as a generic module template for building Transformer components.
Class Signature¶
class Transformer(
src_vocab_size: int,
tgt_vocab_size: int,
d_model: int,
num_heads: int,
num_encoder_layers: int,
num_decoder_layers: int,
dim_feedforward: int,
dropout: float = 0.1,
)
Parameters¶
src_vocab_size (int): Size of the source vocabulary.
tgt_vocab_size (int): Size of the target vocabulary.
d_model (int): Dimension of the model’s hidden representations.
num_heads (int): Number of attention heads in the multi-head self-attention mechanism.
num_encoder_layers (int): Number of encoder layers in the Transformer.
num_decoder_layers (int): Number of decoder layers in the Transformer.
dim_feedforward (int): Dimension of the feedforward network within each layer.
dropout (float, optional): Dropout probability applied throughout the model. Default is 0.1.
Examples¶
>>> import lucid.models as models
>>> transformer = models.Transformer(
... src_vocab_size=5000,
... tgt_vocab_size=5000,
... d_model=512,
... num_heads=8,
... num_encoder_layers=6,
... num_decoder_layers=6,
... dim_feedforward=2048,
... dropout=0.1
... )
>>> print(transformer)
Transformer(src_vocab_size=5000, tgt_vocab_size=5000, d_model=512, ...)
This implementation follows the standard Transformer architecture and is ready to be trained for sequence-to-sequence tasks like machine translation.
Differences from nn.Transformer¶
This class implements a complete Transformer model, including positional encoding and the final projection to vocabulary space.
nn.Transformer, in contrast, provides a modular base class for constructing Transformer components but does not include full integration.