PVT¶
Transformer Vision Transformer Image Classification
- class lucid.models.PVT(img_size: int = 224, num_classes: int = 1000, patch_size: int = 16, in_channels: int = 3, embed_dims: list[int] = [64, 128, 256, 512], num_heads: list[int] = [1, 2, 4, 8], mlp_ratios: list[float] = [4.0, 4.0, 4.0, 4.0], qkv_bias: bool = False, qk_scale: float | None = None, drop_rate: float = 0.0, attn_drop_rate: float = 0.0, drop_path_rate: float = 0.0, norm_layer: type[~lucid.nn.module.Module] = <class 'lucid.nn.modules.norm.LayerNorm'>, depths: list[int] = [3, 4, 6, 3], sr_ratios: list[float] = [8.0, 4.0, 2.0, 1.0])¶
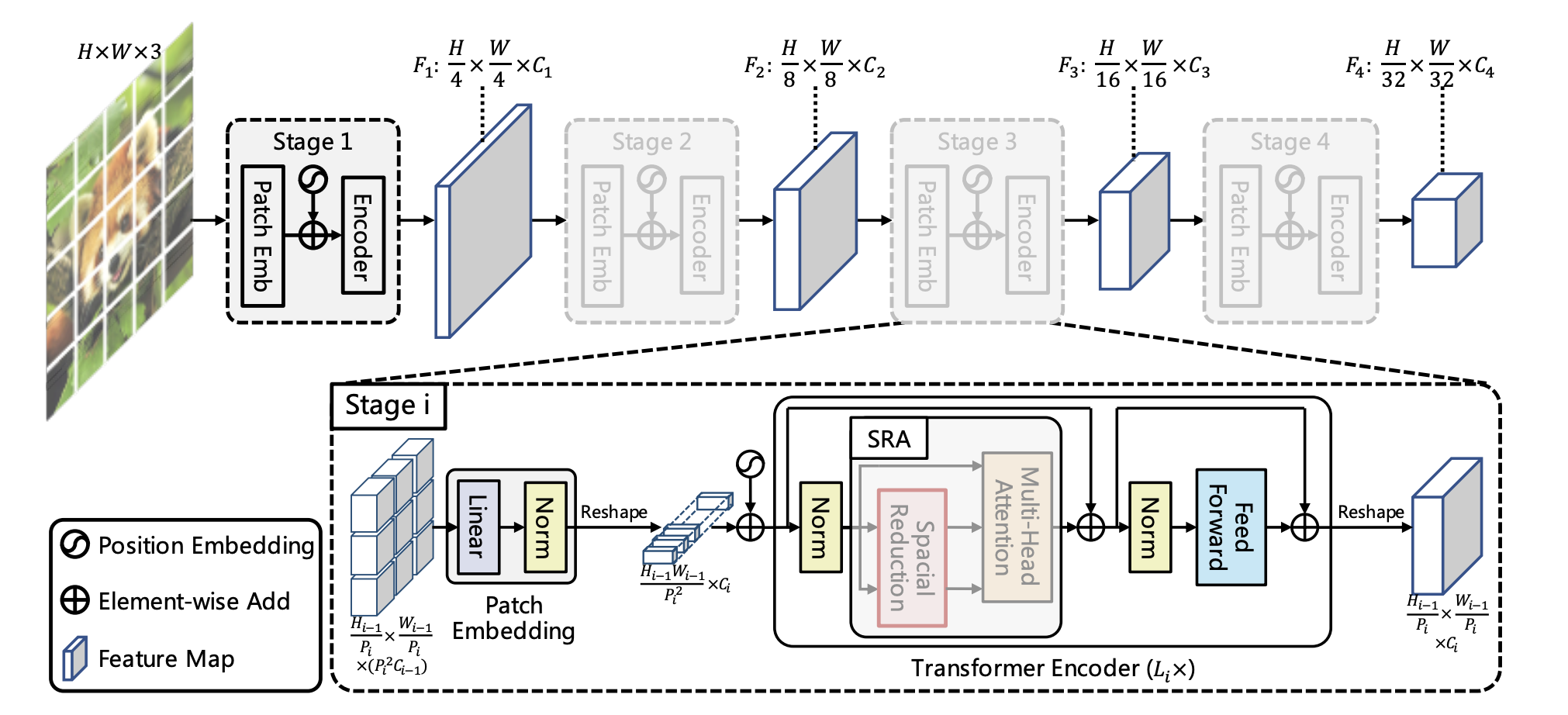
The PVT class implements the Pyramid Vision Transformer (PVT), a hierarchical vision transformer designed for image classification. PVT introduces a multi-stage architecture with progressive spatial reduction, enabling efficient modeling of global and local features. The model supports various configurations for embedding dimensions, attention heads, depth, and other hyperparameters.
Function Signature¶
class PVT(nn.Module):
def __init__(
self,
img_size: int = 224,
num_classes: int = 1000,
patch_size: int = 16,
in_channels: int = 3,
embed_dims: list[int] = [64, 128, 256, 512],
num_heads: list[int] = [1, 2, 4, 8],
mlp_ratios: list[float] = [4.0, 4.0, 4.0, 4.0],
qkv_bias: bool = False,
qk_scale: float | None = None,
drop_rate: float = 0.0,
attn_drop_rate: float = 0.0,
drop_path_rate: float = 0.0,
norm_layer: type[nn.Module] = nn.LayerNorm,
depths: list[int] = [3, 4, 6, 3],
sr_ratios: list[float] = [8.0, 4.0, 2.0, 1.0],
) -> None
Parameters¶
img_size (int, optional): The input image size. Default is 224.
num_classes (int, optional): The number of output classes for classification. Default is 1000.
patch_size (int, optional): The size of image patches processed by the model. Default is 16.
in_channels (int, optional): The number of input channels. Default is 3 (for RGB images).
embed_dims (list[int], optional): A list specifying the embedding dimensions at different stages of the model. Default is [64, 128, 256, 512].
num_heads (list[int], optional): A list specifying the number of attention heads in each stage. Default is [1, 2, 4, 8].
mlp_ratios (list[float], optional): The expansion ratio for the MLP layers in each stage. Default is [4.0, 4.0, 4.0, 4.0].
qkv_bias (bool, optional): Whether to use bias in the query, key, and value projections. Default is False.
qk_scale (float | None, optional): Custom scaling factor for query-key dot product attention. Default is None.
drop_rate (float, optional): Dropout probability for MLP layers. Default is 0.0.
attn_drop_rate (float, optional): Dropout probability for attention weights. Default is 0.0.
drop_path_rate (float, optional): Stochastic depth dropout rate. Default is 0.0.
norm_layer (type[nn.Module], optional): Normalization layer used in the transformer blocks. Default is nn.LayerNorm.
depths (list[int], optional): A list specifying the number of transformer blocks in each stage. Default is [3, 4, 6, 3].
sr_ratios (list[float], optional): A list specifying the spatial reduction ratio for key and value projections in each stage. Default is [8.0, 4.0, 2.0, 1.0].
Returns¶
PVT: An instance of the PVT class representing a Pyramid Vision Transformer.
Examples¶
>>> import lucid.models as models
>>> model = models.PVT()
>>> print(model)
PVT(img_size=224, num_classes=1000, patch_size=16, embed_dims=[64, 128, 256, 512],
num_heads=[1, 2, 4, 8], depths=[3, 4, 6, 3], sr_ratios=[8.0, 4.0, 2.0, 1.0], ...)