MobileNet_V3¶
ConvNet Image Classification
- class lucid.models.MobileNet_V3(bottleneck_cfg: list, last_channels: int, num_classes: int = 1000)¶
Overview¶
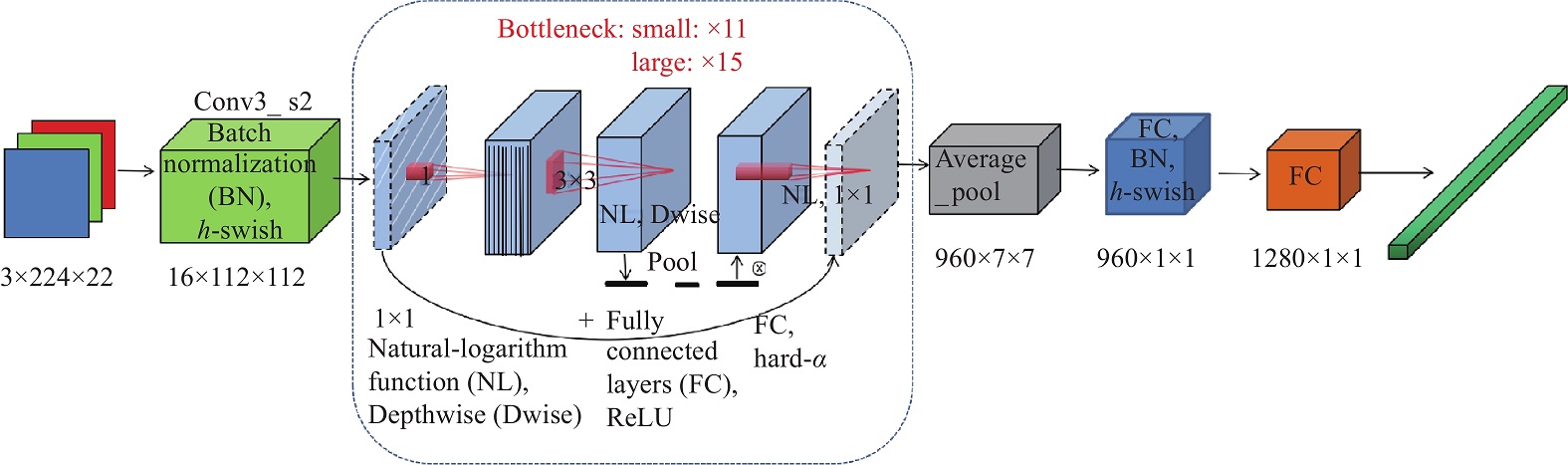
The MobileNetV3 class implements the MobileNet-v3 architecture, building upon the innovations of MobileNet-v2 with further optimizations. It introduces squeeze-and-excitation modules, efficient head designs, and two variants—Small and Large—tailored for different resource constraints.
This architecture is designed for high performance in mobile and embedded applications with minimal computational overhead.
Class Signature¶
class MobileNet_V3(nn.Module):
def __init__(
self, bottleneck_cfg: list, last_channels: int, num_classes: int = 1000
) -> None
Parameters¶
bottleneck_cfg (list): Configuration of bottleneck layers, defining the structure and number of each inverted residual block.
last_channels (int): Number of channels in the final convolutional layer.
num_classes (int, optional): Number of output classes for the classification task. Default is 1000, commonly used for ImageNet.
Examples¶
Creating a MobileNetV3 model with custom configurations:
>>> import lucid.nn as nn
>>> bottleneck_cfg = [
... # (kernel_size, expansion_factor, out_channels, stride)
... (3, 16, 16, 1),
... (3, 64, 24, 2),
... (5, 72, 40, 2),
... # Additional layers can be added as per requirement
... ]
>>> model = nn.MobileNet_V3(bottleneck_cfg=bottleneck_cfg, last_channels=1280, num_classes=1000)
>>> print(model)
Forward pass with MobileNetV3:
>>> from lucid.tensor import Tensor
>>> input_tensor = Tensor([[...]]) # Input tensor with appropriate shape
>>> output = model(input_tensor)
>>> print(output)
Note
The MobileNetV3 architecture is optimized for resource efficiency and high performance on edge devices. Depending on your use case, you can adjust the bottleneck configurations and final output channels to balance accuracy and computational cost.