DETR¶
Transformer Detection Transformer Object Detection
- class lucid.models.DETR(backbone: _BackboneBase, transformer: _Transformer, num_classes: int, num_queries: int = 100, aux_loss: bool = True, matcher: _HungarianMatcher | None = None, class_loss_coef: float = 1.0, bbox_loss_coef: float = 5.0, giou_loss_coef: float = 2.0, eos_coef: float = 0.1)¶
DETR (DEtection TRansformer) is a fully end-to-end object detector that replaces hand-crafted components (anchors, NMS) with a Transformer encoder-decoder. It predicts a fixed set of objects via learned object queries and trains with bipartite (Hungarian) matching and a set-based loss (classification + box L1 + GIoU).
Note
This implementation follows the baseline DETR: ResNet backbone -> 1x1 conv to d_model -> Transformer (6 enc/6 dec by default) -> class and box heads. It supports auxiliary losses from intermediate decoder layers.
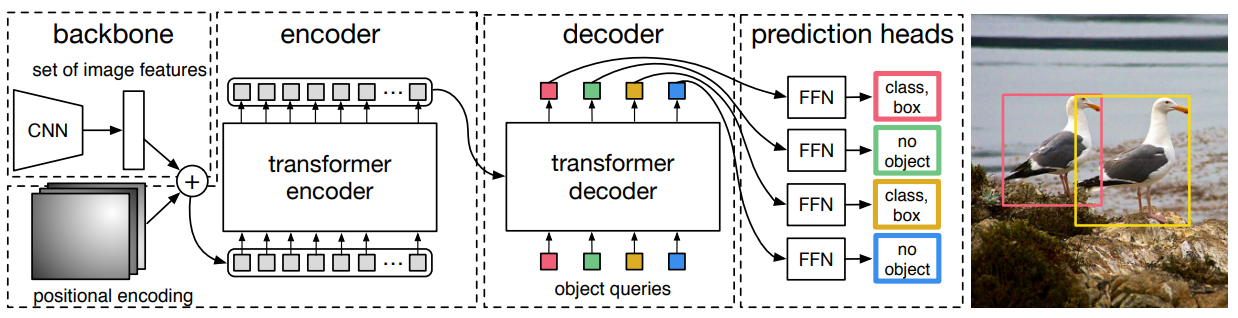
Class Signature¶
class DETR(nn.Module):
def __init__(
self,
backbone: _BackboneBase,
transformer: _Transformer,
num_classes: int,
num_queries: int = 100,
aux_loss: bool = True,
matcher: _HungarianMatcher | None = None,
class_loss_coef: float = 1.0,
bbox_loss_coef: float = 5.0,
giou_loss_coef: float = 2.0,
eos_coef: float = 0.1,
) -> None
Parameters¶
backbone (_BackboneBase): CNN feature extractor (e.g., ResNet-50/101). Outputs a single stride-32 feature map (B, C_backbone, H, W) and a padding mask (B, H, W).
transformer (_Transformer): Encoder-decoder with hidden size d_model (e.g., 256), 8 heads, 6 layers enc/dec by default. Positional encoding must also use d_model.
num_classes (int): Number of foreground categories (COCO: 91).
num_queries (int, default 100): Learned object queries = maximum detections per image.
aux_loss (bool, default True): If True, returns and trains on intermediate decoder outputs.
matcher (_HungarianMatcher | None): Bipartite matcher used during training. Defaults to standard DETR costs if None.
class_loss_coef (float, default 1.0): Weight for classification (CE) loss.
bbox_loss_coef (float, default 5.0): Weight for L1 loss on boxes.
giou_loss_coef (float, default 2.0): Weight for (1 - GIoU) loss on boxes.
eos_coef (float, default 0.1): Weight for the “no-object” class in CE (down-weights background).
Inputs¶
x (Tensor): Input image batch of shape (B, 3, H, W). Images are typically resized so the short side ~ 800 and long side \(\le\) 1312, then padded to multiples of 32.
mask (Tensor[bool], optional): Padding mask (B, H, W) where True marks padded (invalid) pixels. If omitted, an all-False mask is assumed.
Targets (Training)¶
Provide a list of length B. Each element is a dict with:
“class_id”: Tensor[int64] of shape (N_i,) with class indices in [0, num_classes-1].
“box”: Tensor[float32] of shape (N_i, 4) with normalized boxes in (cx, cy, w, h) format, values in [0, 1] relative to the input image size (after any resize/pad).
Important
Boxes must be center-x, center-y, width, height in [0,1]. If your dataset is in pixels and/or xyxy, convert before passing targets.
Returns¶
Evaluation / Inference (`aux_loss=False`)
pred_logits: (B, num_queries, num_classes + 1) - raw class scores; the last channel is “no-object”.
pred_boxes: (B, num_queries, 4) - normalized (cx, cy, w, h) in [0,1].
Training / Aux mode (`aux_loss=True`)
A list: intermediate decoder outputs followed by the final output. Each element is a tuple: (pred_logits_l, pred_boxes_l) with the same shapes as above.
Loss & Matching¶
Training uses Hungarian matching between predictions and ground-truth objects with the following costs:
Classification (CE) with “no-object” eos_coef (e.g., 0.1).
L1 box loss (weight = bbox_loss_coef, default 5.0).
Generalized IoU loss (weight = giou_loss_coef, default 2.0).
The total DETR loss is the weighted sum over matched pairs; unmatched queries are trained toward “no-object”.
Details¶
Backbone projection: a 1x1 conv maps backbone channels to d_model before flattening.
Positional encoding: sine-cosine 2D encoding with num_pos_feats = d_model // 2; shape (B, d_model, H, W).
Queries: learnable embeddings of shape (num_queries, d_model).
Decoder outputs: each query yields one class distribution and one box.
Auxiliary losses: if enabled, identical heads are applied to intermediate decoder layers (deep supervision).
Methods¶
Examples¶
Forward (inference)¶
import lucid
from lucid.models import detr_r50
model = detr_r50(pretrained_backbone=True, num_classes=91, num_queries=100, aux_loss=False).eval()
x = lucid.random.randn(1, 3, 800, 800)
logits, boxes = model(x) # (1, 100, 92), (1, 100, 4)
probs = lucid.softmax(logits, axis=-1)[..., :-1] # drop no-object
scores = probs.max(axis=-1) # (1, 100)
Targets format¶
# Single image example (B=1) with two objects
target = {
"class_id": lucid.tensor([5, 17], dtype=lucid.Int64),
"box": lucid.tensor([[0.52, 0.44, 0.20, 0.25],
[0.28, 0.70, 0.15, 0.10]], dtype=lucid.Float32)
}
targets = [target]
Training step (sketch)¶
model.train()
# Example loss call
loss = model.get_loss(x, targets)
Note
No NMS: DETR does not require non-maximum suppression at inference time.
num_queries: controls the maximum number of detections per image (default 100).
Input size: commonly short side ~ 800, long side \(\le\) 1312, padded to /32. The model supports arbitrary sizes.