YOLO-v4¶
ConvNet One-Stage Detector Object Detection
- class lucid.models.YOLO_V4(num_classes: int, anchors: list[list[tuple[int, int]]] | None = None, strides: list[int] | None = None, backbone: Module | None = None, backbone_out_channels: tuple[int, int, int] | None = None, in_channels: tuple[int, int, int] = (256, 512, 1024), pos_iou_thr: float = 0.25, ignore_iou_thr: float = 0.5, obj_balance: tuple[float, float, float] = (4.0, 1.0, 0.4), cls_label_smoothing: float = 0.0, iou_aware_alpha: float = 0.5, iou_branch_weight: float = 1.0)¶
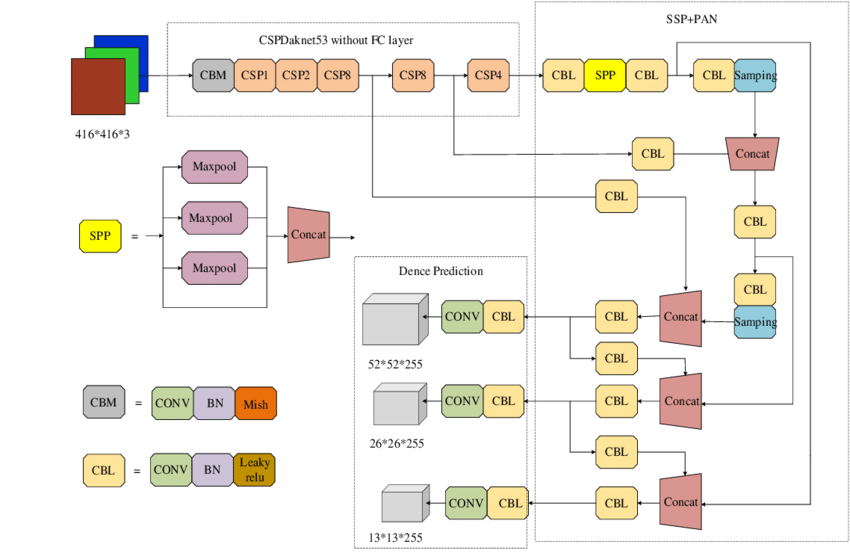
The YOLO_V4 class implements the YOLO-v4 object detection model, extending YOLO-v3 with architectural and training improvements for better accuracy and speed. It includes CSP-DarkNet-53 as a backbone, SPP and PANet as necks, and enhancements like Mish activation and label smoothing.
Class Signature¶
class YOLO_V4(
num_classes: int,
anchors: list[list[tuple[int, int]]] | None = None,
strides: list[int] | None = None,
backbone: nn.Module | None = None,
backbone_out_channels: tuple[int, int, int] | None = None,
in_channels: tuple[int, int, int] = (256, 512, 1024),
pos_iou_thr: float = 0.25,
ignore_iou_thr: float = 0.5,
obj_balance: tuple[float, float, float] = (4.0, 1.0, 0.4),
cls_label_smoothing: float = 0.0,
iou_aware_alpha: float = 0.5,
iou_branch_weight: float = 1.0,
)
Parameters¶
num_classes (int): Number of object classes for detection.
anchors (list[list[tuple[int, int]]], optional): 3-scale list of anchor box groups. Each inner list holds 3 anchor tuples. Defaults to YOLO-v4 anchors if None.
strides (list[int], optional): Strides for the 3 detection heads (typically [8, 16, 32]).
backbone (nn.Module, optional): Optional feature extractor (default: CSP-DarkNet-53).
backbone_out_channels (tuple[int, int, int], optional): Output channels from backbone corresponding to 3 detection scales.
in_channels (tuple[int, int, int]): Input channels to the necks (SPP, PANet).
pos_iou_thr (float): Positive label threshold for anchor assignment.
ignore_iou_thr (float): IOU threshold above which anchor is ignored in loss.
obj_balance (tuple[float, float, float]): Weights for objectness loss at different scales.
cls_label_smoothing (float): Smoothing factor for classification targets.
iou_aware_alpha (float): Weight for combining IOU and objectness predictions.
iou_branch_weight (float): Loss weight for IOU-aware branch.
Attributes¶
backbone (nn.Module): Backbone network for feature extraction.
Methods¶
Architectural Improvements¶
YOLO-v4 introduces major changes in both backbone and neck compared to YOLO-v3:
Backbone:
Uses CSP-DarkNet-53 instead of Darknet-53 for better feature reuse and reduced computation.
Necks:
SPP (Spatial Pyramid Pooling):
Expands receptive field by applying multiple max-pooling operations in parallel.
Concatenates pooled features with original feature map for enhanced context.
PAN (Path Aggregation Network):
Strengthens bottom-up path to better propagate low-level localization features.
Improves multi-scale feature fusion compared to YOLO-v3’s basic FPN.
Other Enhancements:
Mish activation in early layers.
DropBlock, CIoU Loss, and Self-Adversarial Training for regularization.
Label Smoothing, Cosine Annealing, and IoU-aware objectness.
Multi-Scale Detection¶
YOLO-v4 detects objects at 3 spatial resolutions:
13x13 (stride=32): large objects
26x26 (stride=16): medium objects
52x52 (stride=8): small objects
Each scale predicts 3 bounding boxes per grid cell using separate anchors.
Input Format¶
Targets should be a tuple of 3 tensors (one per scale):
(N, Hs, Ws, B * (5 + C))
Where:
Hs, Ws: grid size (13, 26, 52)
B: number of anchors per scale (typically 3)
C: number of classes
Each vector contains:
\((t_x, t_y, t_w, t_h, obj, cls_1, \dots, cls_C)\)
Where:
\(t_{x,y}\): cell-relative offsets in [0,1]
\(t_{w,h}\): log-scale of width/height to anchor
\(obj\): 1 if responsible, else 0
\(cls\): one-hot encoding of class
YOLO-v4 Loss¶
YOLO-v4 applies scale-weighted composite loss:
Where:
\(\hat{C}\): objectness score after sigmoid
\(\hat{p}(c)\): predicted class probability
\(\hat{iou}\): predicted IOU confidence (optional)
Prediction Output¶
The predict method returns a list of detections per image:
“box”: [x1, y1, x2, y2] in pixels
“score”: objectness x class probability
“class_id”: predicted class index
Example Usage¶
Using YOLO-V4 with default neck and backbone
>>> from lucid.models import YOLO_V4
>>> model = YOLO_V4(num_classes=80)
>>> x = lucid.random.rand(1, 3, 416, 416)
>>> detections = model.predict(x)
>>> print(detections[0][0])
Backward Propagation¶
YOLO-V4 supports end-to-end gradient training:
>>> x = lucid.random.rand(1, 3, 416, 416, requires_grad=True)
>>> targets = (...) # Ground truth tuple for 3 scales
>>> loss = model.get_loss(x, targets)
>>> loss.backward()
>>> print(x.grad)